捕获组
捕获组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用。
当然,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部。
捕获组的编号规则
编号规则指的是以数字为捕获组进行编号的规则,在普通捕获组或命名捕获组单独出现的正则表达式中,编号规则比较清晰,在普通捕获组与命名捕获组混合出现的正则表达式中,捕获组的编号规则稍显复杂。
在展开讨论之前,需要说明的是,编号为0的捕获组,指的是正则表达式整体,这一规则在支持捕获组的语言中,基本上都是适用的。下面对其它编号规则逐一展开讨论。
普通捕获组编号规则
如果没有显式为捕获组命名,即没有使用命名捕获组,那么需要按数字顺序来访问所有捕获组。在只有普通捕获组的情况下,捕获组的编号是按照“(”出现的顺序,从左到右,从1开始进行编号的 。
正则表达式:(\d{4})-(\d{2}-(\d\d))
上面的正则表达式可以用来匹配格式为yyyy-MM-dd的日期,为了在下表中得以区分,月和日分别采用了\d{2}和\d\d这两种写法。
用以上正则表达式匹配字符串:2008-12-31,匹配结果为: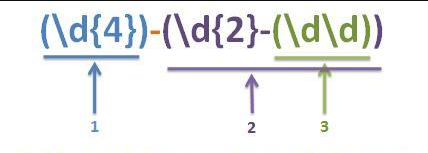
捕获组引用
对捕获组的引用一般有以下几种:
- 正则表达式中,对前面捕获组捕获的内容进行引用,称为反向引用;
- 正则表达式中,(?(name)yes|no)的条件判断结构;
- 在程序中,对捕获组捕获内容的引用。
反向引用
捕获组捕获到的内容,不仅可以在正则表达式外部通过程序进行引用,也可以在正则表达式内部进行引用,这种引用方式就是反向引用。
反向引用的作用通常是用来查找或限定重复,限定指定标识配对出现等等。
对于普通捕获组和命名捕获组的引用,语法如下:
普通捕获组反向引用:\k
命名捕获组反向引用:\k
普通捕获组反向引用中number是十进制的数字,即捕获组的编号;命名捕获组反向引用中的name为命名捕获组的组名。
反向引用匹配原理
捕获组(Expression)在匹配成功时,会将子表达式匹配到的内容,保存到内存中一个以数字编号的组里,可以简单的认为是对一个局部变量进行了赋值,这时就可以通过反向引用方式,引用这个局部变量的值。一个捕获组(Expression)在匹配成功之前,它的内容可以是不确定的,一旦匹配成功,它的内容就确定了,反向引用的内容也就是确定的了。
反向引用必然要与捕获组一同使用的,如果没有捕获组,而使用了反向引用的语法,不同语言的处理方式不一致,有的语言会抛异常,有的语言会当作普通的转义处理。
举个例子
源字符串:abcdebbcde
正则表达式:([ab])\1
对于正则表达式“([ab])\1”,捕获组中的子表达式“[ab]”虽然可以匹配“a”或者“b”,但是捕获组一旦匹配成功,反向引用的内容也就确定了。如果捕获组匹配到“a”,那么反向引用也就只能匹配“a”,同理,如果捕获组匹配到的是“b”,那么反向引用也就只能匹配“b”。由于后面反向引用“\1”的限制,要求必须是两个相同的字符,在这里也就是“aa”或者“bb”才能匹配成功。
考察一下这个正则表达式的匹配过程,在位置0处,由“([ab])”匹配“a”成功,将捕获的内容保存在编号为1的组中,然后把控制权交给“\1”,由于此时捕获组已记录了捕获内容为“a”,“\1”也就确定只有匹配到“a”才能匹配成功,这里显然不满足,“\1”匹配失败,由于没有可供回溯的状态,整个表达式在位置0处匹配失败。
正则引擎向前传动,在位置5之前,“([ab])”一直匹配失败。传动到位置5处时,,“([ab])”匹配到“b”,匹配成功,将捕获的内容保存在编号为1的组中,然后把控制权交给“\1”,由于此时捕获组已记录了捕获内容为“b”,“\1”也就确定只有匹配到“b”才能匹配成功,满足条件,“\1”匹配成功,整个表达式匹配成功,匹配结果为“bb”,匹配开始位置为5,结束位置为7。
扩展一下,正则表达式“([a-z])\1{2}”也就表达连续三个相同的小写字母。
:joy: